文生图ai视频
2025-03-29 22:00:18
使用AI技术生成视频,特别是基于文本描述来生成图像并进一步制作成视频的过程,可以分为几个主要步骤。下面我将这一过程简化为4个基本步骤,以帮助你理解整个流程:
● 第一步:文本输入与解析
- 目标:明确你想通过视频表达的内容。
- 操作:首先,你需要提供一段详细的文本描述,这段描述应该尽可能地具体和形象化,包括场景设置、角色特征、动作细节等信息。然后,利用自然语言处理技术对这段文本进行分析,提取关键元素如人物、地点、时间、情绪等。
● 第步二:图像生成
- 目标:根据第一步解析出的信息,创建符合描述的图像。
- 操作:使用预训练好的深度学习模型(如GANs, Diffusion Models等),依据上一步得到的关键信息自动生成对应的图像。这一步可能需要多次迭代调整参数或微调模型,直到产出满意的视觉效果为止。
● 第三步:视频合成
- 目标:将多个静态图像组合起来形成连贯流畅的动画片段。
- 操作:选择合适的工具或者软件(例如Adobe After Effects, Blender等)来编排这些图像,并添加过渡效果、背景音乐以及文字说明等内容。此外,还可以应用一些高级技巧如运动追踪、粒子系统等增加视频的真实感和吸引力。
● 第四步:后期编辑与优化
- 目标:提升视频质量,确保最终成品能够准确传达原意且具有良好的观看体验。
- 操作:对初步完成的视频进行细致审查,针对色彩校正、音效同步、字幕准确性等方面做进一步修改和完善。必要时还可以邀请专业人士参与评审,收集反馈意见后再次调整直至满意为止。
请注意,实际操作过程中每个环节都可能遇到各种挑战,比如如何提高图像生成的质量、怎样保证视频内容的原创性和版权问题等。随着技术的进步,这些问题正在逐步得到解决,但现阶段仍然需要用户具备一定的专业知识和技术背景才能顺利完成整个创作流程。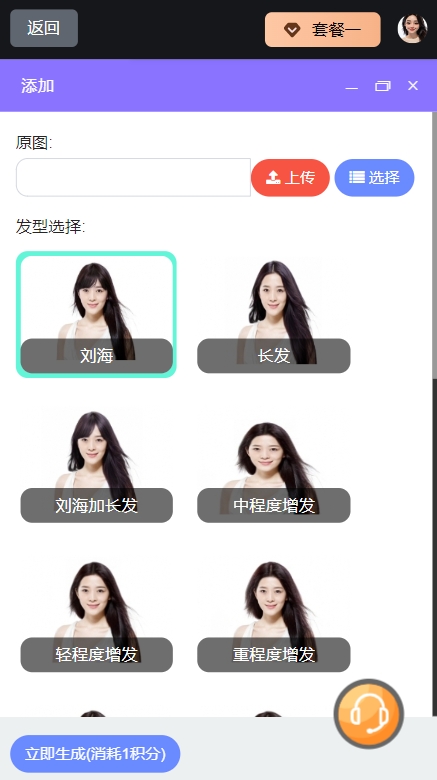
● 第一步:文本输入与解析
- 目标:明确你想通过视频表达的内容。
- 操作:首先,你需要提供一段详细的文本描述,这段描述应该尽可能地具体和形象化,包括场景设置、角色特征、动作细节等信息。然后,利用自然语言处理技术对这段文本进行分析,提取关键元素如人物、地点、时间、情绪等。
● 第步二:图像生成
- 目标:根据第一步解析出的信息,创建符合描述的图像。
- 操作:使用预训练好的深度学习模型(如GANs, Diffusion Models等),依据上一步得到的关键信息自动生成对应的图像。这一步可能需要多次迭代调整参数或微调模型,直到产出满意的视觉效果为止。
● 第三步:视频合成
- 目标:将多个静态图像组合起来形成连贯流畅的动画片段。
- 操作:选择合适的工具或者软件(例如Adobe After Effects, Blender等)来编排这些图像,并添加过渡效果、背景音乐以及文字说明等内容。此外,还可以应用一些高级技巧如运动追踪、粒子系统等增加视频的真实感和吸引力。
● 第四步:后期编辑与优化
- 目标:提升视频质量,确保最终成品能够准确传达原意且具有良好的观看体验。
- 操作:对初步完成的视频进行细致审查,针对色彩校正、音效同步、字幕准确性等方面做进一步修改和完善。必要时还可以邀请专业人士参与评审,收集反馈意见后再次调整直至满意为止。
请注意,实际操作过程中每个环节都可能遇到各种挑战,比如如何提高图像生成的质量、怎样保证视频内容的原创性和版权问题等。随着技术的进步,这些问题正在逐步得到解决,但现阶段仍然需要用户具备一定的专业知识和技术背景才能顺利完成整个创作流程。
同类文章推荐

ai绘画文生图
AI绘画文生图,即通过人工智能技术将文字描述转化为图像的过程。这一过程...
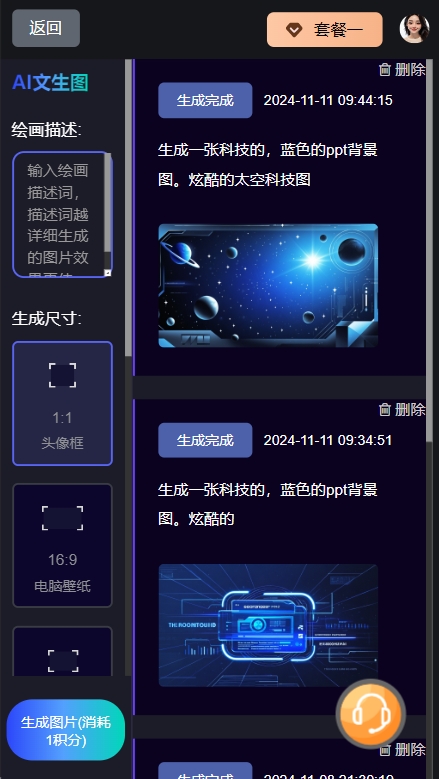
文生图软件操作视频
文生图软件通常指的是能够将文字描述转换成图像的软件。这类软件利用了人工...
手机文生图软件
使用手机上的文生图软件,可以将文字描述转化为图像。以下是分5步来说明如...
谷歌文生图软件
谷歌并没有直接推出一个名为“文生图”的特定软件,但可能您指的是使用谷歌...

生图修图软件
使用生图修图软件进行图片编辑,可以分为以下五个步骤。这里以一个通用流程...

ai文生图翻译
AI文生图翻译可以理解为利用人工智能技术将文本描述转换成图像的过程。这...
怎么ai生图
使用AI生成图像通常涉及以下三个基本步骤: 1. **选择合适的AI...
文生图小程序源码
开发一个基于文本生成图像的小程序,可以分为三个主要步骤:需求分析与准备...