ai文字生图源码
2025-03-29 13:38:28
AI文字生图,也被称为文本到图像的生成技术,是一种利用深度学习模型将自然语言描述转换为视觉图像的技术。实现这一功能的过程可以大致分为五个步骤来说明,这里我将提供一个简化的概述,而非具体的源代码实现,因为这涉及到复杂的算法和大量的数据处理。
● 第一步:准备环境与数据
1. 安装必要的库:首先需要在你的开发环境中安装一些基础库,比如TensorFlow或PyTorch等深度学习框架。
2. 收集训练数据集:对于文本到图像的任务来说,你需要一个包含大量图片及其对应描述的数据集。DALL-E、COCO Caption等是常用的数据集。
3. 预处理数据:对收集到的数据进行清洗(如去除无效信息)、标准化(如调整所有图片至相同尺寸)等预处理工作。
● 第二步:设计模型架构
选择合适的神经网络架构对于构建高效的文本到图像生成器至关重要。常见的选择包括但不限于:
- 使用编码器-解码器结构,其中编码器负责理解输入文本,而解码器则基于此信息生成图像。
- 应用GANs (Generative Adversarial Networks) 或者变体,如BigGAN,它们通过对抗训练过程来提高生成图像的质量。
- 利用Transformer模型处理文本部分,并结合卷积神经网络(CNN)或其他图像生成技术完成图像合成。
● 第三步:训练模型
1. 定义损失函数:根据所选模型的特点选择合适的损失函数,例如交叉熵损失、均方误差等。
2. 设置优化器:选择适合你问题的优化算法,如Adam、RMSprop等。
3. 开始训练:使用准备好的数据集开始训练模型。这通常是一个迭代过程,在每个epoch之后评估模型性能并调整参数以改善结果。
● 第四步:测试与调优
1. 验证模型效果:使用一部分未参与训练的数据作为测试集,检查模型在新样本上的表现如何。
2. 调整超参数:根据测试反馈调整学习率、批次大小等超参数,以获得更好的生成效果。
3. 增加正则化:如果遇到过拟合问题,可以通过添加Dropout层、L2正则化等方式减轻。
● 第五步:部署应用
一旦模型训练完成并且达到了满意的性能水平,就可以将其部署到实际的应用场景中去了。这可能意味着将其集成到Web服务、移动应用程序或者其他平台之上,以便用户能够通过简单的接口提交文本请求并接收生成的图像。
请注意,上述步骤仅为概念性指导,具体实现时还需要考虑更多细节和技术挑战。此外,由于版权及伦理考量,在使用任何公开可用的数据集前,请确保遵守相关法律法规。
● 第一步:准备环境与数据
1. 安装必要的库:首先需要在你的开发环境中安装一些基础库,比如TensorFlow或PyTorch等深度学习框架。
2. 收集训练数据集:对于文本到图像的任务来说,你需要一个包含大量图片及其对应描述的数据集。DALL-E、COCO Caption等是常用的数据集。
3. 预处理数据:对收集到的数据进行清洗(如去除无效信息)、标准化(如调整所有图片至相同尺寸)等预处理工作。
● 第二步:设计模型架构
选择合适的神经网络架构对于构建高效的文本到图像生成器至关重要。常见的选择包括但不限于:
- 使用编码器-解码器结构,其中编码器负责理解输入文本,而解码器则基于此信息生成图像。
- 应用GANs (Generative Adversarial Networks) 或者变体,如BigGAN,它们通过对抗训练过程来提高生成图像的质量。
- 利用Transformer模型处理文本部分,并结合卷积神经网络(CNN)或其他图像生成技术完成图像合成。
● 第三步:训练模型
1. 定义损失函数:根据所选模型的特点选择合适的损失函数,例如交叉熵损失、均方误差等。
2. 设置优化器:选择适合你问题的优化算法,如Adam、RMSprop等。
3. 开始训练:使用准备好的数据集开始训练模型。这通常是一个迭代过程,在每个epoch之后评估模型性能并调整参数以改善结果。
● 第四步:测试与调优
1. 验证模型效果:使用一部分未参与训练的数据作为测试集,检查模型在新样本上的表现如何。
2. 调整超参数:根据测试反馈调整学习率、批次大小等超参数,以获得更好的生成效果。
3. 增加正则化:如果遇到过拟合问题,可以通过添加Dropout层、L2正则化等方式减轻。
● 第五步:部署应用
一旦模型训练完成并且达到了满意的性能水平,就可以将其部署到实际的应用场景中去了。这可能意味着将其集成到Web服务、移动应用程序或者其他平台之上,以便用户能够通过简单的接口提交文本请求并接收生成的图像。
请注意,上述步骤仅为概念性指导,具体实现时还需要考虑更多细节和技术挑战。此外,由于版权及伦理考量,在使用任何公开可用的数据集前,请确保遵守相关法律法规。
同类文章推荐

ai绘画文生图
AI绘画文生图,即通过人工智能技术将文字描述转化为图像的过程。这一过程...
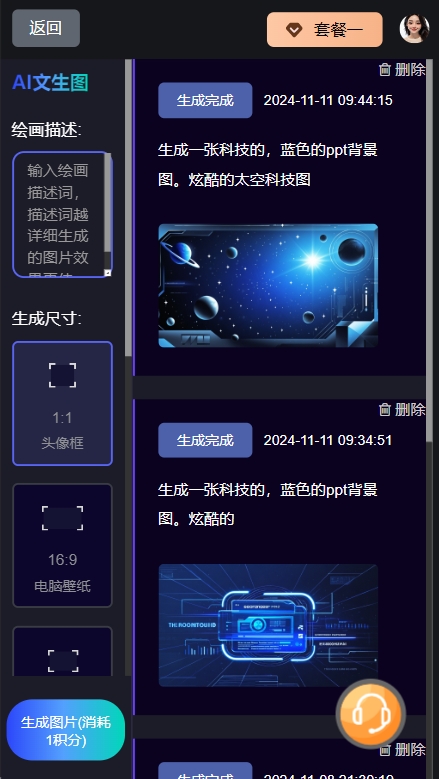
文生图软件操作视频
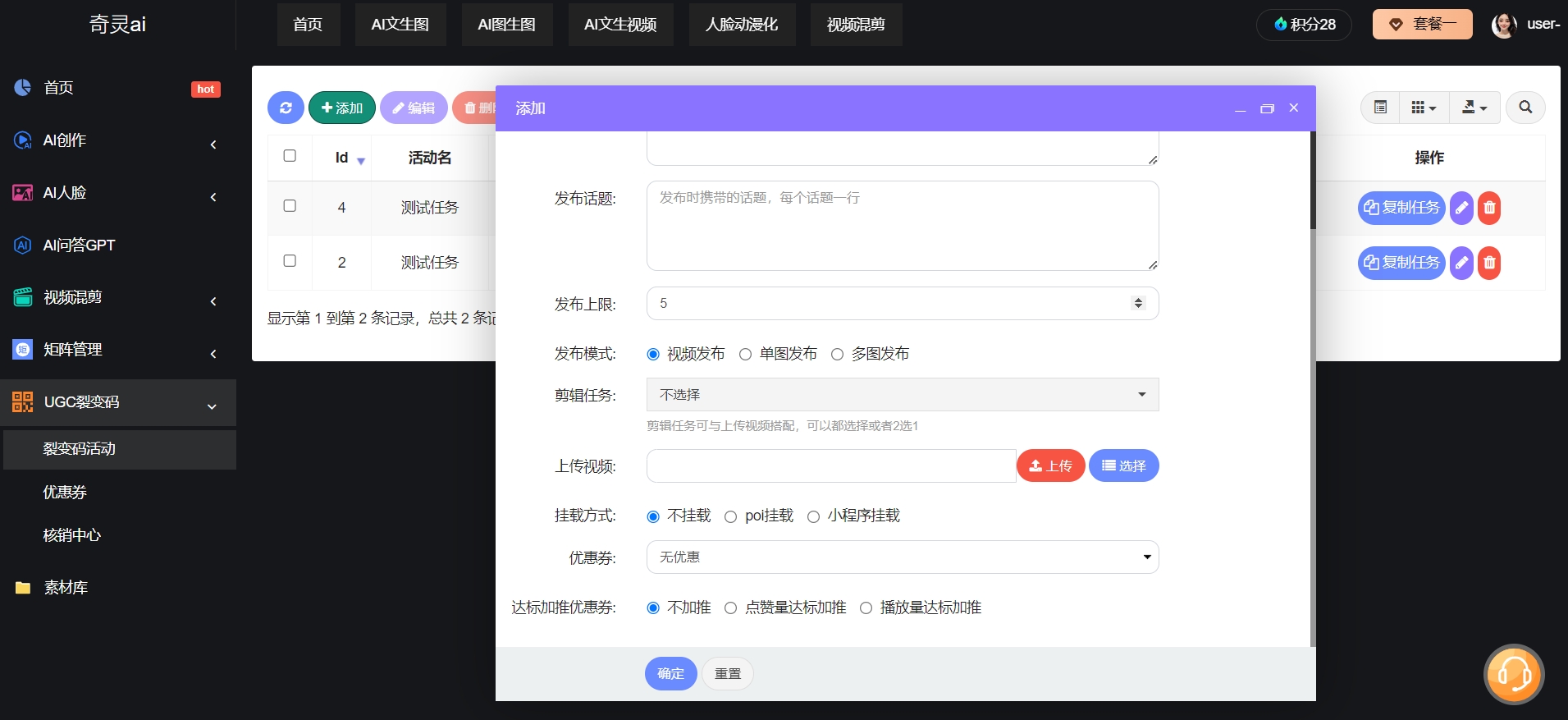
文生图软件通常指的是能够将文字描述转换成图像的软件。这类软件利用了人工...
手机文生图软件
使用手机上的文生图软件,可以将文字描述转化为图像。以下是分5步来说明如...
谷歌文生图软件
谷歌并没有直接推出一个名为“文生图”的特定软件,但可能您指的是使用谷歌...

生图修图软件
使用生图修图软件进行图片编辑,可以分为以下五个步骤。这里以一个通用流程...

ai文生图翻译
AI文生图翻译可以理解为利用人工智能技术将文本描述转换成图像的过程。这...
怎么ai生图
使用AI生成图像通常涉及以下三个基本步骤: 1. **选择合适的AI...
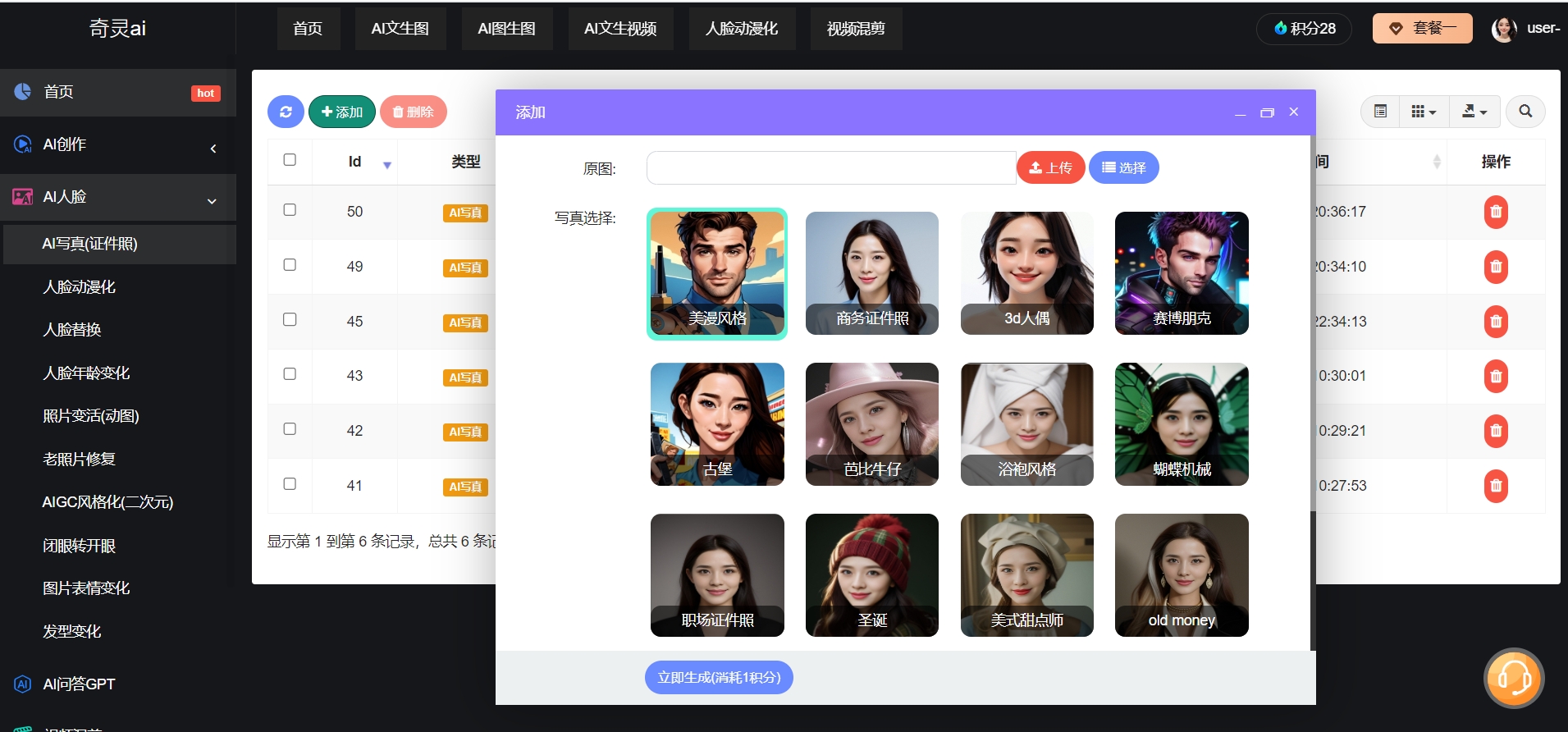
文生图小程序源码
开发一个基于文本生成图像的小程序,可以分为三个主要步骤:需求分析与准备...